Morgan Wynne

An innovative, hardworking team player with a can-do attitude and passion for solving problems with data and machine learning.
View My LinkedIn Profile
Data Science, Analytics & Engineering Projects
Machine Learning Projects
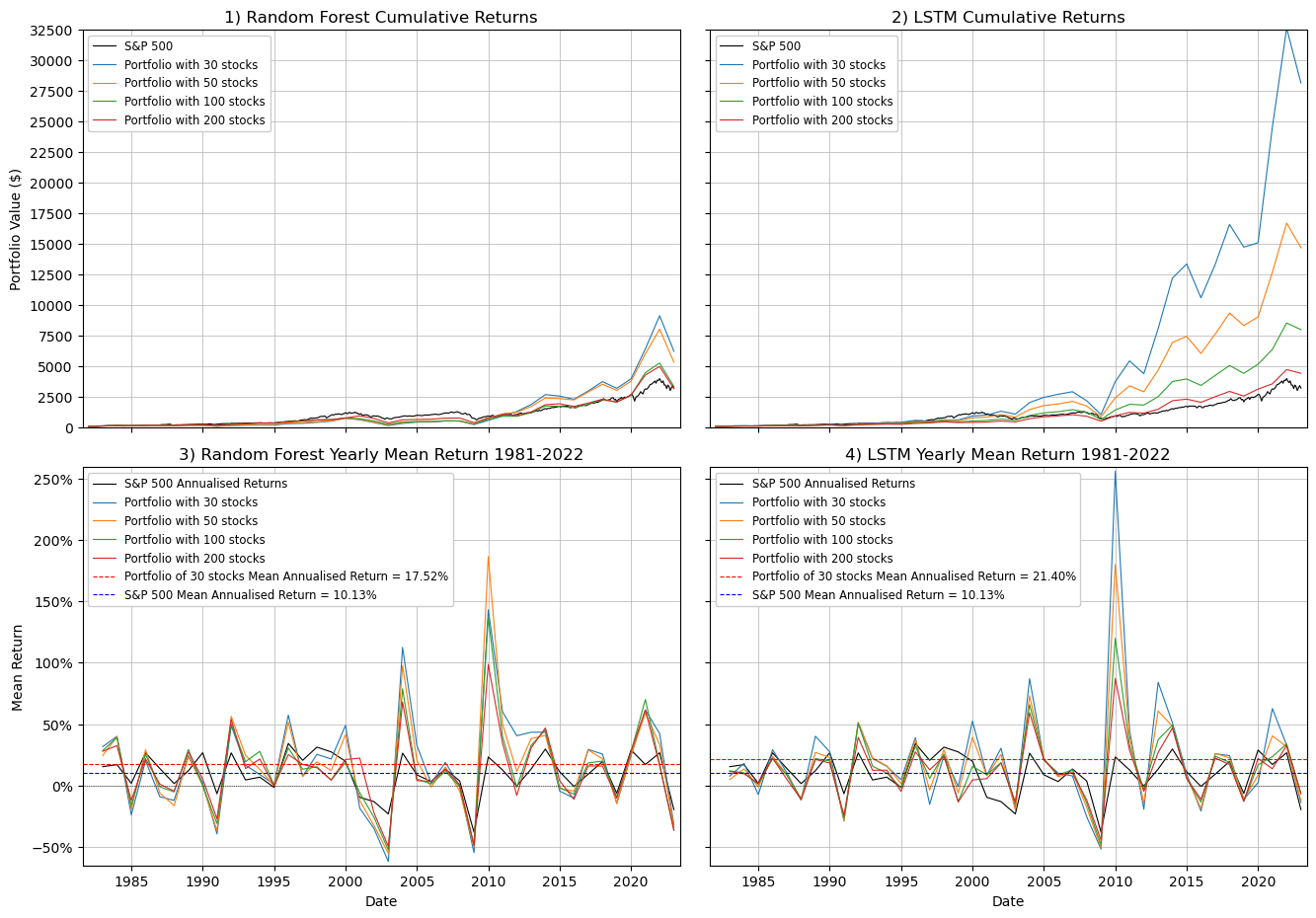
Long-term Stock Selection using Random Forest and LSTM Models for Fundamental Analysis
Completed as my MSc Thesis, this project applied investment principles and machine learning models to select annual portfolios of stocks that would outperform the S&P 500 benchmark index. This involved processing a very large dataset of North American fundamental stock data, exploring and visualising the dataset, applying various machine learning models, including Random Forest Regressor (sklearn) and Long-Short Term Memory (PyTorch) models, and simulating and evaluating their performance over a 40-year test period 1980-2022.
Please click here to view the github repository containing the code (run in AWS Sagemaker), or here to view the full thesis as a PDF.
HSBC University Group Project - Using Machine Learning Methods to Extract Trading Signals from Limit Order Book Market Data
This was a 13-week university group project supported by the HSBC Artificial Intelligence team. We were challenged to use machine learning algorithms to generate profits in active trading using level-2 limit order book data. Our execution compared the performance of an highly interpretable decision tree model using handcrafted, interpretable features (e.g. Limit order book imbalance, 10-second order flow imbalance, etc.) with a more complex but less interpretable Convolutional Neural Network (CNN) model that used unsupervised feature extraction. We created an innovative way to overcome problems associated with market illiquidity and both models generated consistently profitable outcomes in 2 weeks of active trading.
Please click here to view the github repository, or here to view the full PDF.
Various Natural Language Processing Projects
I completed various NLP coursework projects during my MSc that involved creating NLP pre-processing pipelines and applying a whole range of probabilistic and discriminative ML models; from traditional models like Naive Bayes and Hidden Markov Models to state-of-the-art neural networks like LSTM and transformer-based LLMs. Tasks included:
- Financial news sentiment classification (Multinomial Naive Bayes)
- Social media posts topic modelling (Latent Dirichlet Allocation)
- Named entity recognition for identifying genes in scientific documents (Conditional Random Field)
- Tweet sentiment classification (FF Neural Network)
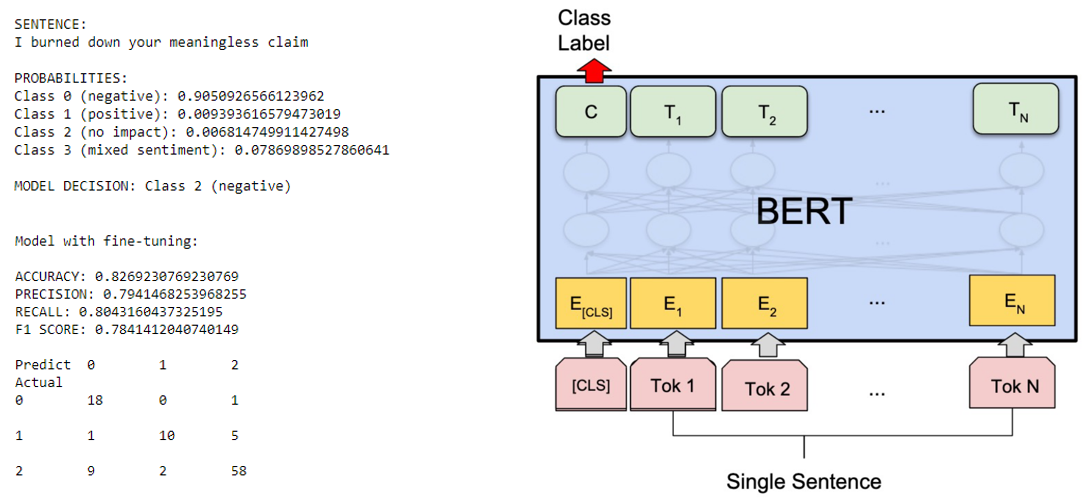
- Question answering (pre-trained transformer TinyBERT model)
- Poem sentiment classification (fine-tuned transformer TinyBERT model with classification head)
Please click here to view the github repository.
Comparison of Various Machine Learning Models for Predicting Hourly Energy Usage of a Power Plant
This project compared the performances of a Random Forest and Multi-Layer Perceptron to that of a baseline univariate linear regression model for predicting the energy usage of a power plant. Cross-validation was used to optimise model hyperparameters and the performance of each model was evaluated using R-squared and RMSE.
Please click here to view the github repository containing the jupyter notebook, or here to view the full PDF write-up.
Information Visualisation Projects
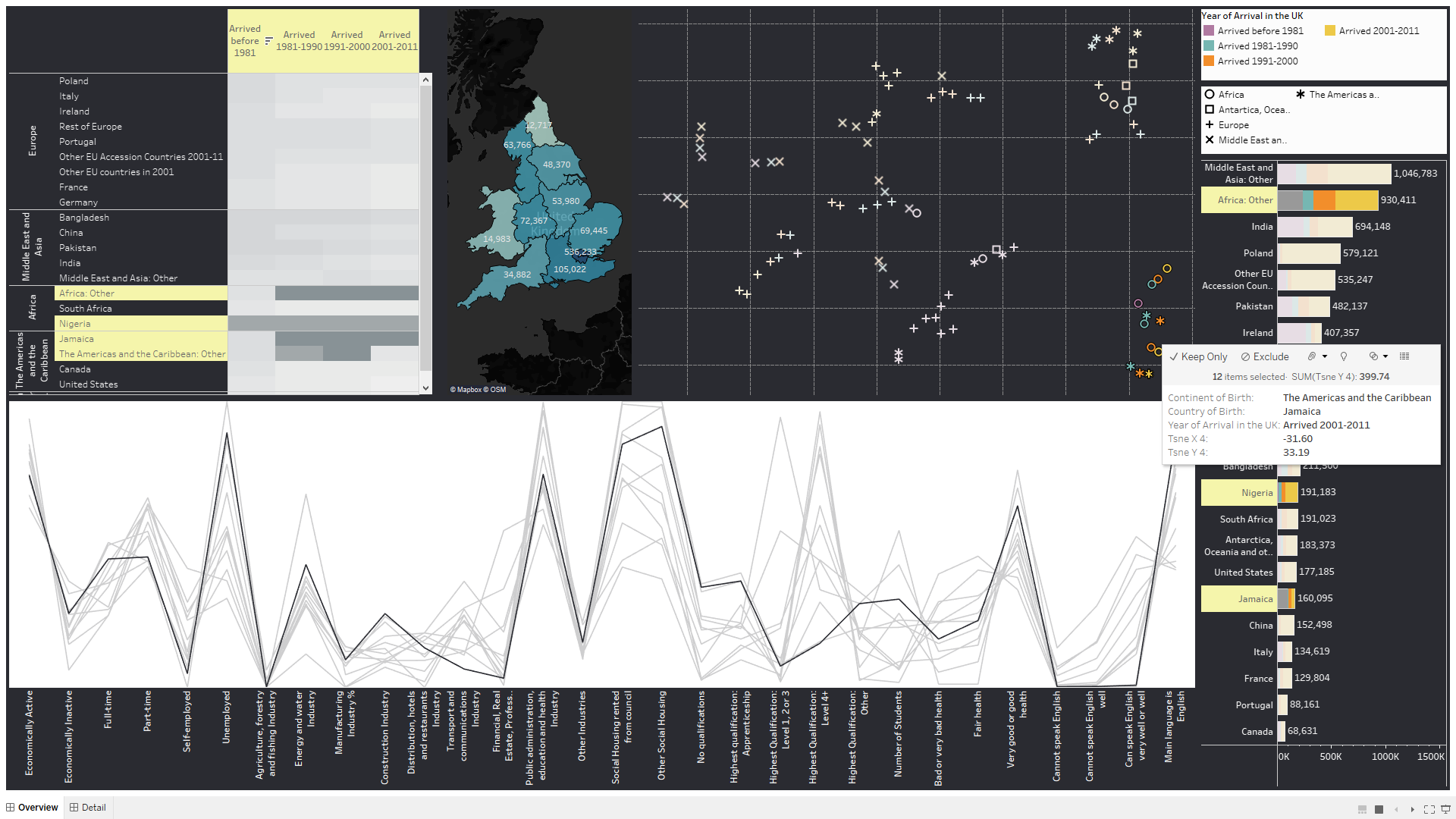
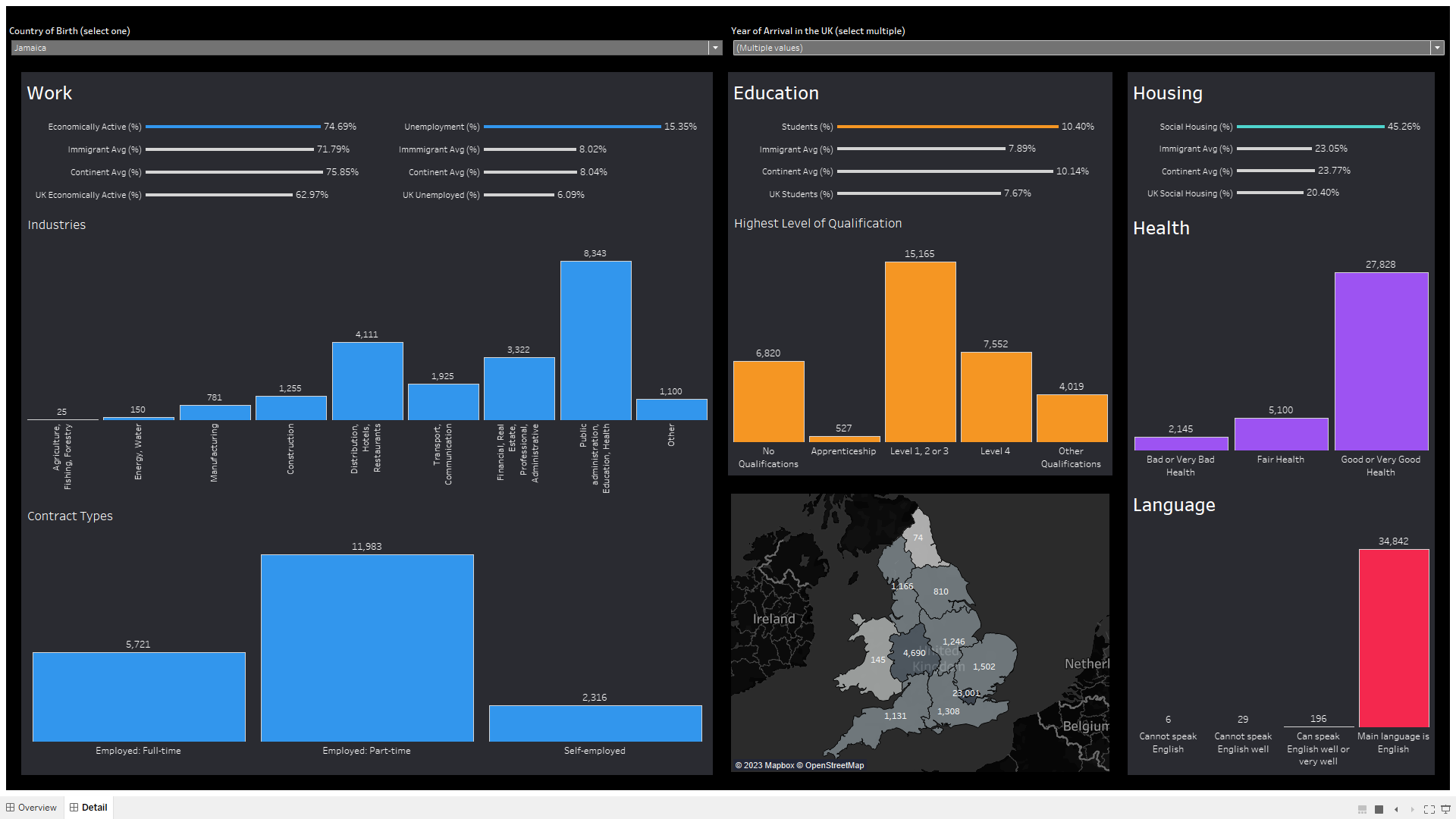
Identifying Key Demographic Features of UK Immigrants
This project used 2011 census data, t-Stochastic Neighbourhood Embedding, and Tableau to create a tool for Home Office officials and NGOs to analyse the UK immigrant population. The tool visualises how 30 key demographic features (collected by ONS) vary across the UK immigrant population by the country an immigrant arrived from and the year of their arrival.
Please click here to download the packaged Tableau workbook.
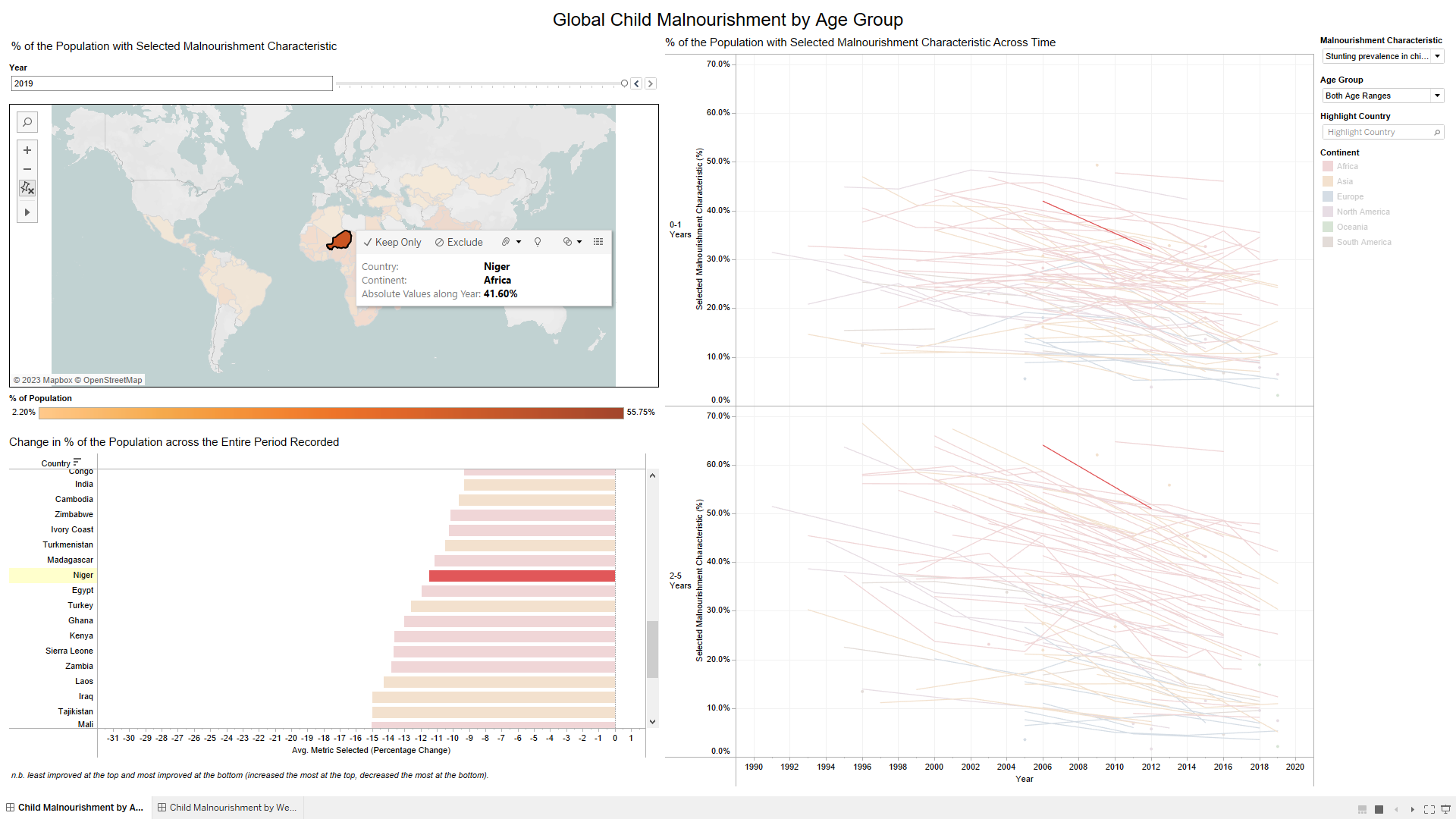
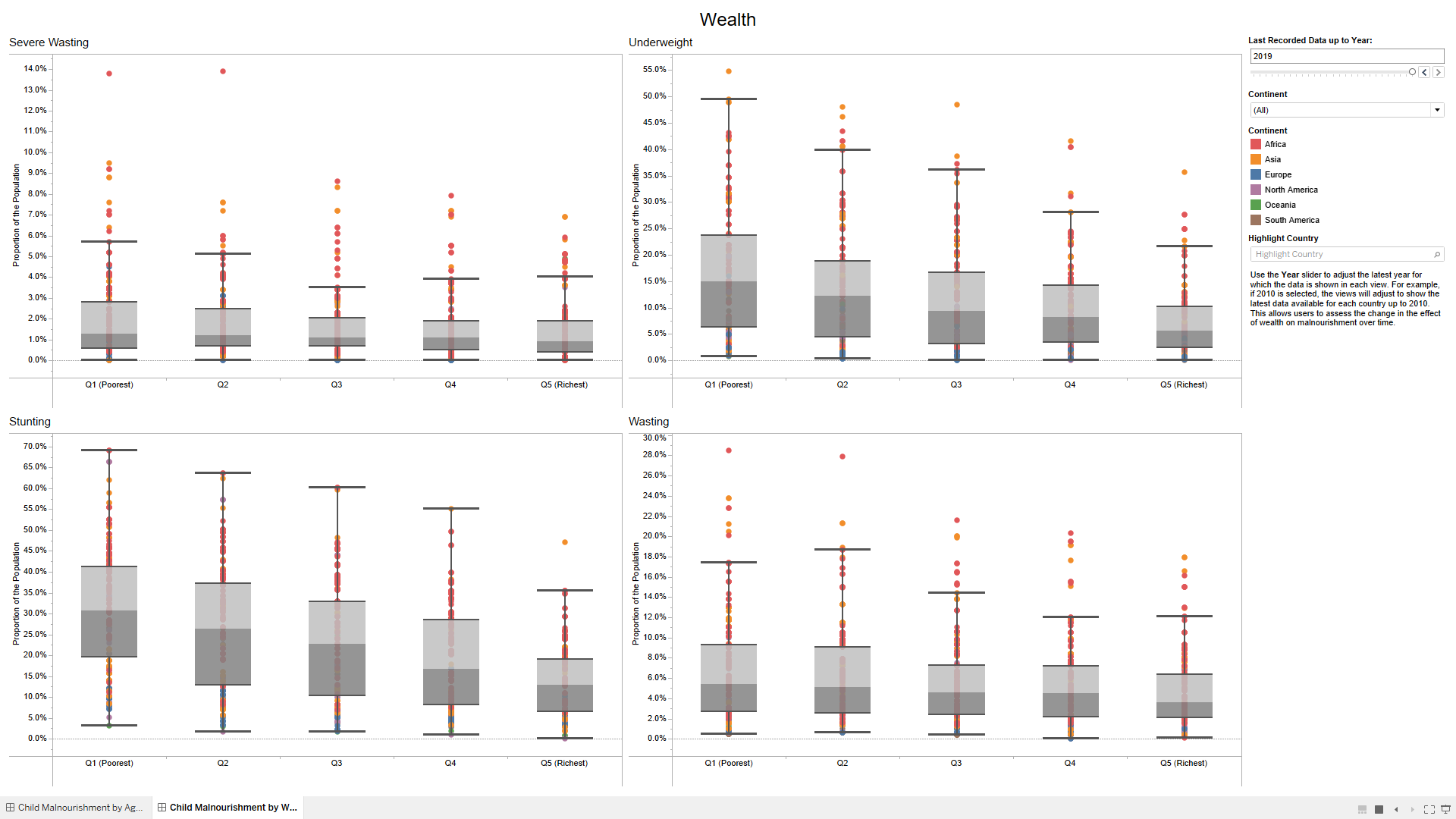
Analysing Global Child Malnourishment
This project uses the principles of information visualisation to analyse the global child malnourishment data provided by WHO. It enables the user to answer three pre-specified questions/tasks:
- In which countries has child malnutrition improved over the period and in which countries has malnutrition got worse?
- Is there a link between wealth and child malnutrition?
- Show the values on a world map with information on both 0-1 years and 2-5 year appropriately presented.
Please click here to download the packaged Tableau workbook.
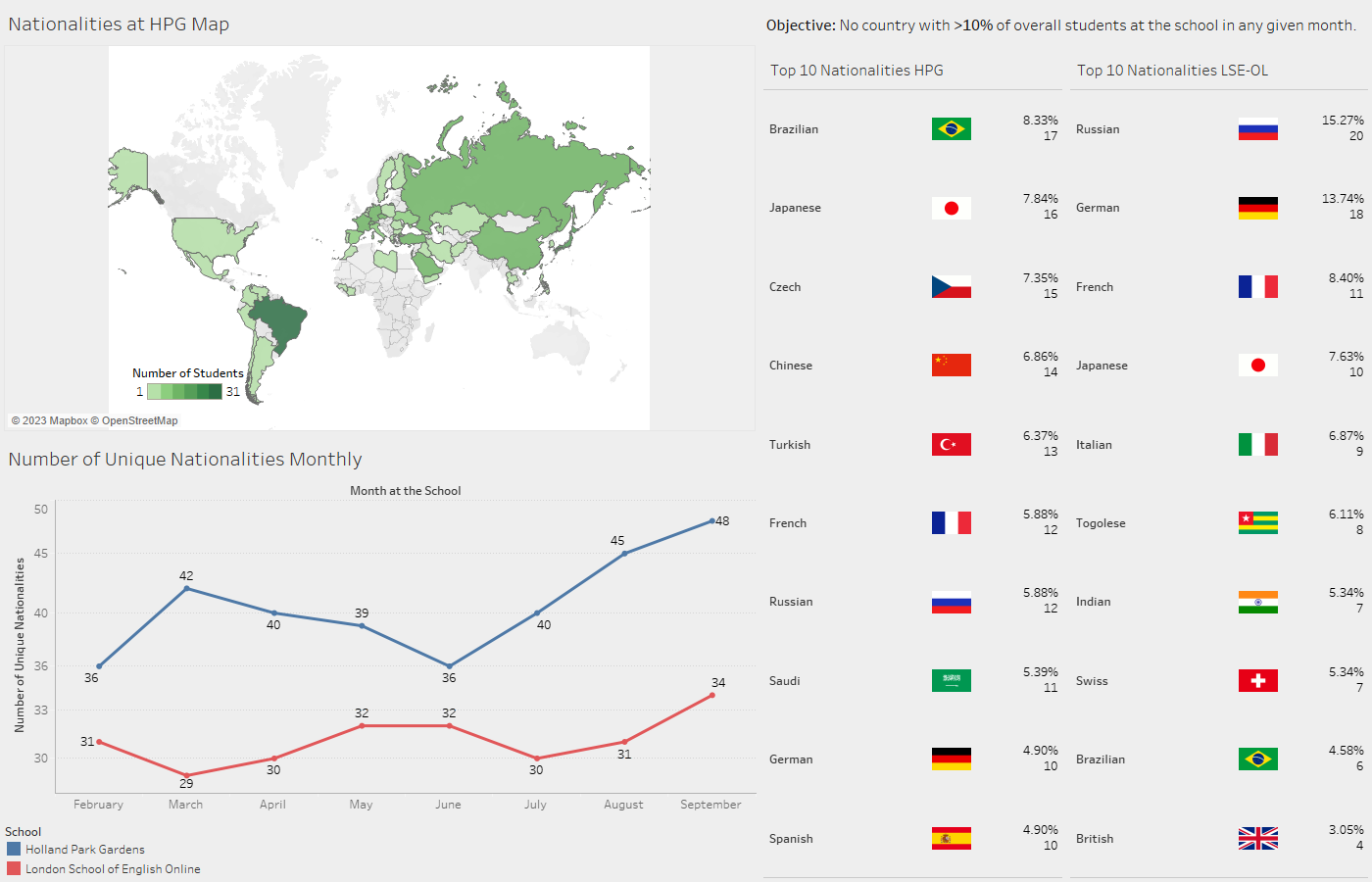
London School of English - Key Performance Indicators
I worked closely with the senior management team at the London School of English to understand the Key Performance Indicators (KPIs) that drive their business. Over several months, I developed a comprehensive process for streamlining data from the company databases and creating a monthly report that is distributed to the board and senior management team each month.
Please click here to download the document for September.
Software Development & Data Engineering Projects
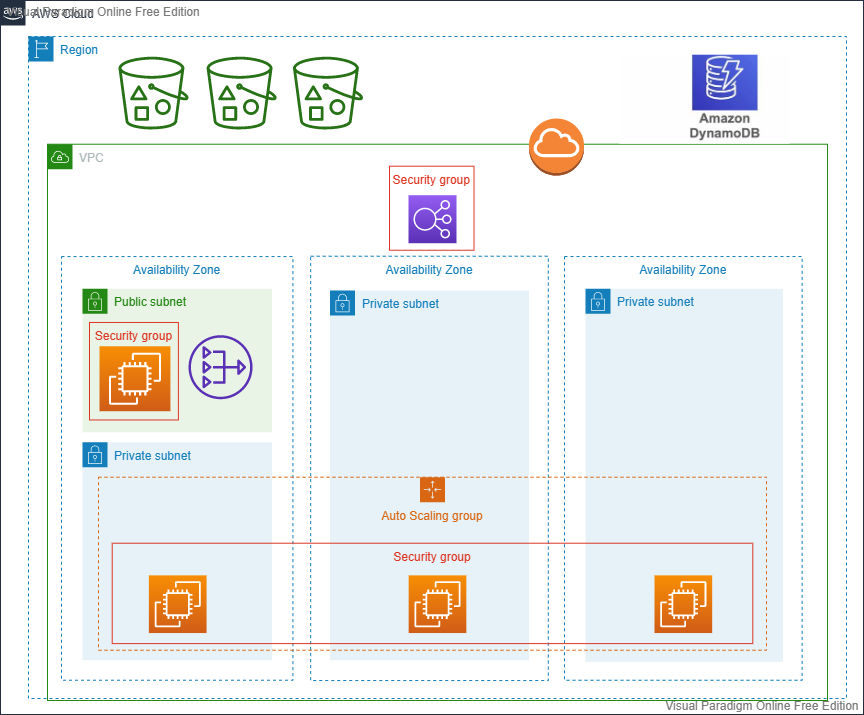
Building a Secure, Resilient, and Scalable Cloud-native Architecture using AWS Cloud
Constructed a scalable, secure, and resilient word counting application in AWS Cloud that stored documents, processed them using queues and messages, and stored results in an Athena database.
Squares Game from Scratch using OOP Principles and only Basic Python Libraries
Programmed a Squares game to be played in the command line using Object Oriented Programming (OOP) principles and using only basic Python libraries. The game included extensive error handling and several play modes, including a smart computer mode.
Please click here to view the github repository.